[ad_1]
In the early days of the open source movement, a lot of the attention was on operating systems, and later on large content management systems. These days, containers are mentioned regularly even in mainstream news outlets. The big tech stories are great, but they miss the other great activity in the niches of the open source space. I’ve rounded up seven interesting lesser-known projects from the past year. You can see more articles about projects like this in my Nooks and Crannies column.
Mixxx: A DJ’s Swiss Army knife
In the late 1980s, I worked as a disc jockey for a local radio station and as a mobile DJ for parties, weddings, and dances. It was a lot of fun and wasn’t a hard business to start. You could set up shop with two CD players, a decent mixer and amplification system, and a lot of CDs. Thirty years later, what sticks in my head was lugging all those CDs. Sampling was virtually unheard of for mobile DJs back then. Commonly available computers were expensive and slow enough that playing music from a PC was risky—it would hang while buffering at some point during a show.
The technology for DJs has dramatically changed in the intervening years. An inexpensive computer can handle everything we could do in the ’80s, and much more. Mixxx is an open source system that acts as a mixer and sampler for a mobile or club DJ. It’s incredibly feature-rich, with four input decks and four sampling decks, tools for synchronization during cross-fades, key detection and pitch shifting for harmonic mixing, and built-in effects. You can play your mixes live, record them, or stream them over the Internet using SHOUTcast or Icecast. Mixxx has an amazing music library system to let you organize your music in any way you like, giving quick access to songs in the library. Mixxx has comprehensive support for DJ hardware controllers, including more than 80 of the most popular models.
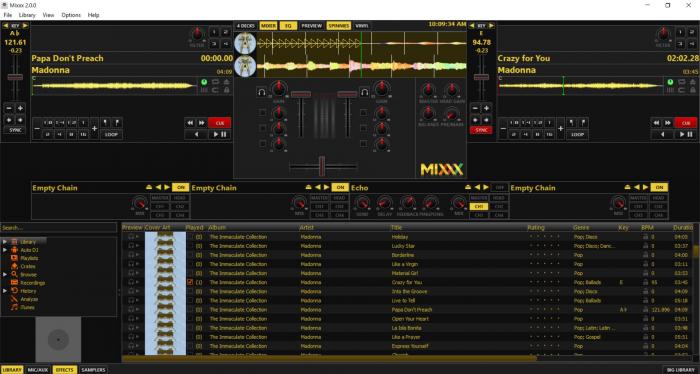 Mixxx, mixing Madonna with herself. Don’t judge my music!
Mixxx, mixing Madonna with herself. Don’t judge my music!I took a look at the Mixxx community, and it’s a robust, well-organized group of dedicated souls with broad diversity. There are forums, a huge wiki, and excellent bug and release tracking all set up and well-established. The community has adopted a well-written code of conduct that discourages problematic behavior among members. On the wiki, you’ll find great tips on hardware for use with Mixxx, and a Getting Involved page that talks about how even non-programmers can get plugged into the Mixxx community. Mixxx is a C++ application and is available under the GPL v2 license for Windows, OS X, and Linux. Version 2.0 came out in December 2015.
sofa: Not a place for lazy data scientists
The R project is a widely used software environment for statistical computing, and its use in data analysis continues to rise. The rOpenSci project is producing tools to allow R to access large repositories of science data and full-text journal articles. One of the tools from the rOpenSci team is sofa. Sofa is a kit of tools for allowing easy access in R to CouchDB NoSQL document databases.
To begin using sofa in a program, you create a server handle, cleverly called a cushion:
myCushion <- Cushion$new(
host = "myhost.mynet.org",
transport = 'https',
port = NULL,
user = 'username',
pass = 'mypassword'
)
Once you have a cushion, you can connect to any database or create and destroy databases. A database creation is as simple as:
db_create(myCushion, 'felines')
Once you’ve created a JSON or XML document, inserting it into the database is easy:
my_kitty <- '{"name":"Midnight", "color":"black", "furry":true, "size":'large', "gender":"tom"}'
doc_create(myCushion, dbname="felines", my_kitty)
You can optionally specify a fourth parameter to the doc_create to force the document ID to a known value. If you don’t use it, the default is to use an automatically generated hash key.
Ready to query? It’s straightforward:
db_query(myCushion, dbname="felines", selector=list(size = 'large'))$docs
This query returns a structure with the full document, including ID and revision for all documents that have a size field of large. There are tools that let you limit your return to specific fields and much more complicated searching than this example.
Sofa is a great tool for unlocking the data in CouchDB; if big data is your game, it might be the right tool for you. All of rOpenSci’s work is MIT licensed and has a contributor code of conduct. The code is available on GitHub.
PANOPTES: Open source astronomy
I interviewed Jennifer Tong and Wilfred Gee from the PANOPTES project in April. I enjoyed their OSCON conference presentation, and have been following their website for more information about this great project. PANOPTES (Panoptic Astronomical Networked OPtical observatory for Transiting Exoplanets Survey) is a project harnessing the power of interested citizen scientists around the world in building a network of robotic telescopes. This global array will detect transiting exoplanets for further examination by larger earth- and space-based telescopes.
Each participant builds a robotic telescope using off-the-shelf equipment: A commercially available camera, an Arduino Micro, an Intel NUC, and other easy-to-find components. You can buy most of the components from Amazon, and the total cost is less than US$ 5,000. These telescopes will share their data with the project servers, and image analysis from many units will go into finding potential results. When desired by the owner, an individual telescope may be taken offline for unrelated observations. This makes it an ideal project for schools and science educators, as they get to be involved in a larger global project, and have access to a quality telescope for their local teaching work.
The PANOPTES project is continuing to refine its hardware design. Beta testers for the system are welcome to build one according to the instructions on the website. Much work also is being done on the centralized observatory control system, which directs each of the robotic telescopes in their observations. This is a project worth watching not just for the science it can do, but for learning about a process for engaging people in other distributed-science teams.
OpenAPS: Enhancing life quality for Type 1 diabetes patients
One of the high-water marks of OSCON this year for me was Dana Lewis’s keynote about OpenAPS, a simplified artificial pancreas for Type 1 diabetes patients. OpenAPS uses currently available medical tools—diabetes pumps and continuous glucose monitors, paired with Raspberry Pi or Intel Edison computers. The system takes care of the complicated calculations that a pump user normally must do to keep their blood glucose levels steady. By updating every five minutes, it’s doing the work in near-real-time 24-hours a day. This means less hassle for the user during the day, and better sleep at night.
The core belief of this effort is that by open sourcing the project code, they can make APS (Artificial Pancreas System) technology available to more people more quickly than current closed-source APS medical research. The OpenAPS team has taken a conservative approach to dosing to help keep it safe as well as effective.
More than 90 units have been deployed, with more than 30 of those in the summer and fall of 2016, and about a third of the OpenAPS users are children. The community is user-led, and new users are welcome. The documentation for building one of your own is freely available and deeply detailed. It explains not only the how but the why; with an emphasis on patient safety.
Many of us who work in IT want to make lives better by making computers do interesting things, and OpenAPS is one of the best examples I’ve found of using our open source skills to help our loved ones.
OpenEMR: Tools for keeping a medical practice organized
I’ve always had the impression that doctor’s offices are quite complex places to work. Lots of diverse information must be kept and secured, and the functions that use patient information are equally diverse. Recently I was surprised to learn about OpenEMR,an open source practice-management system. It’s been around a while, having been first developed in 2001, under another name. The first release was out in 2002, under the GPL V2.0 license.
The feature list is impressive. Besides a robust patient-records system, OpenEMR has a built-in medical billing system that can take part in the major billing clearing houses using ANSI ASC X12 and can use any coding system desired. OpenEMR also handles online prescription ordering, using ePrescribe, as well as more traditional print, fax, or email methods. If installed as a service, OpenEMR also has a patient portal system to handle communications with patients. If an office already has a popular patient portal system in use, the system can communicate via API and use that instead.
 The OpenEMR Patient Information screen
The OpenEMR Patient Information screenOpenEMR offers a staggering list of reports, and one feature that caught my eye is that it is supported in more than 20 languages and has the ability to support multiple languages in the same clinic. This is a nice feature to have in diverse cities with large populations of non-local-language speakers, as each user can choose their own language set. OpenEMR is fully UTF-8 compliant.
With an estimated 5,000+ installs in the US alone, OpenEMR has a thriving community of users and developers. The OEMR Foundation is a US charitable organization set up to support OpenEMR adoption and development to promote more affordable healthcare for all. There are highly active forums for users and developers to discuss their needs and get help with the application. More than 30 companies globally are providing commercial hosting and/or support of OpenEMR. It’s not a Thneed (a fine thing that all people need, according to Dr. Seuss), but it’s certainly a great open source success story.
bibisco: The novelist’s friend
In September 2015, I covered bibisco in my column. Written by Andrea Feccomandi, bibisco is an open source alternative to programs like Scrivener. I was impressed with the polished feature set, and as I said then, I’ve been moving my own novel and other writings into it. There was only one thing holding me back from full-throated enthusiasm for this project, and that was a lack of an OS X client. Andrea packaged it for Windows and 32- and 64-bit Linux. A friend of mine made things sort of work, with a lot of finesse, on his Mac, but it was a mystery to me how to do it.
Bibisco has really revolutionized the way I’m writing my novel. For each of the scenes in a chapter, I’ve got a separate entry with a one-line title describing that scene. I can use these entries as a storyboard for the chapter, rearranging them as I desire. Each chapter can be tagged with locations and characters, and I can get reports on how often those appear across the book. I’ve made a fair bit of progress since finishing the switchover, and I couldn’t be happier. There was that one nagging little problem, though. I could only work on the novel at home where I have a Windows machine; my Macbook just couldn’t do it. Imagine my surprise a few days after the release of the article when Andrea commented and told the world that he had purchased a Mac so that he could release the OS X client. Then, a month later, he commented again, announcing the release of the OS X client on the website.
Pa11y: Automated accessibility testing
One oft-ignored element of web design is accessibility. Many of the guidelines are hard to test, but there are a number of specific, testable criteria that designers can use—if they have the right tool for the job. Enter Pa11y, a suite of tools for one-off or automated testing of web pages for accessibility against a broad list of criteria sets. Installation of the basic toolkit is easy with npm, so you can test your pages right away and get feedback and specific suggestions for improvement. If your organization would like to do ongoing or periodic testing of pages, installing the dashboard and web service is straightforward. You can see a demo of this dashboard at demo.pa11y.org.
The community is actively working on a new version of its website, which includes much more detailed information for developers and others wanting to contribute. The group has adopted a code of conduct adapted from the Contributor Covenant. They are also beginning work on a new, more refined version of the dashboard application called Sidekick. Coding has begun on that project, which the team is dedicated to designing and developing completely in the open, in a GitHub repository.
And more
Every year, several hundred new open source projects appear. As much as I’d love to, covering them all is not possible. The projects in this roundup are only a few of the many worth watching in the next year. Let us know about your project—submit an article proposal.
[ad_2]
Source link